AI 모델 성능을 결정짓는 데이터 전처리: 최신 전략과 실무 노하우
AI 모델의 성능은 데이터의 질이 결정합니다. 최근 주목받는 '목표 힌트(Goal Hint)' 기법부터 LoRA 학습을 위한 이미지 정규화, 그리고 거대 언어 모델(LLM)의 한계를 극복하는 실용적인 전처리 전략을 소개합니다.
1. 데이터의 의도를 명확히: '목표 힌트(Goal Hint)'의 도입
많은 개발자가 데이터 전처리를 단순한 '노이즈 제거'나 '포맷 통일'로만 생각하는 경향이 있습니다. 하지만 최근 AI 에이전트 연구 트렌드, 특히 2026년 초반의 논문 흐름을 살펴보면 데이터에 '방향성'을 부여하는 것이 중요해졌습니다. 그중 핵심이 바로 '목표 힌트(Goal Hint)'입니다.
에이전트가 방대한 문서를 읽을 때 단순히 내용을 벡터화하는 것을 넘어, "지금 무엇을 찾고 있는지"를 명시적으로 데이터 로딩 단계에서 주입하는 기법입니다. 예를 들어, 유지보수(MRO) 관련 문서를 처리할 때 "MRO 해석 로직에 집중하라"는 힌트를 메타데이터나 프롬프트 전처리 단계에 포함시키면, AI가 불필요한 배경 지식보다는 핵심 로직을 우선적으로 추출하게 됩니다. 이는 RAG(검색 증강 생성) 시스템의 정확도를 획기적으로 높이는 실용적인 전략입니다.

2. 멀티모달 시대의 전처리: LoRA와 이미지 최적화
텍스트를 넘어 이미지 생성 모델이나 비전 모델을 다룰 때는 더욱 섬세한 전처리가 요구됩니다. 최근 유튜브 요약 노트나 기술 커뮤니티에서 공유되는 LoRA(Low-Rank Adaptation) 훈련 팁을 보면, 단순히 이미지 크기를 조정(Resizing)하는 것만으로는 부족합니다.
성능 극대화를 위해서는 정규화(Normalization)와 정교한 캡셔닝이 필수적입니다. 이미지의 픽셀 값을 모델이 학습하기 좋은 범위로 조정하고, 이미지의 내용을 텍스트로 설명하는 캡셔닝 단계에서 구체적인 키워드를 배치해야 고품질 데이터셋이 구축됩니다. 또한, 텍스트 데이터 처리 시 채팅창의 입력 한계(Context Window)에 부딪히는 경우가 많은데, 이를 극복하기 위해 '구글 문서' 등을 활용하여 AI가 생성한 1차 딥 리서치 결과물 전체를 하나의 컨텍스트로 묶어 처리하는 방식도 실무에서 유용한 꿀팁으로 활용되고 있습니다.

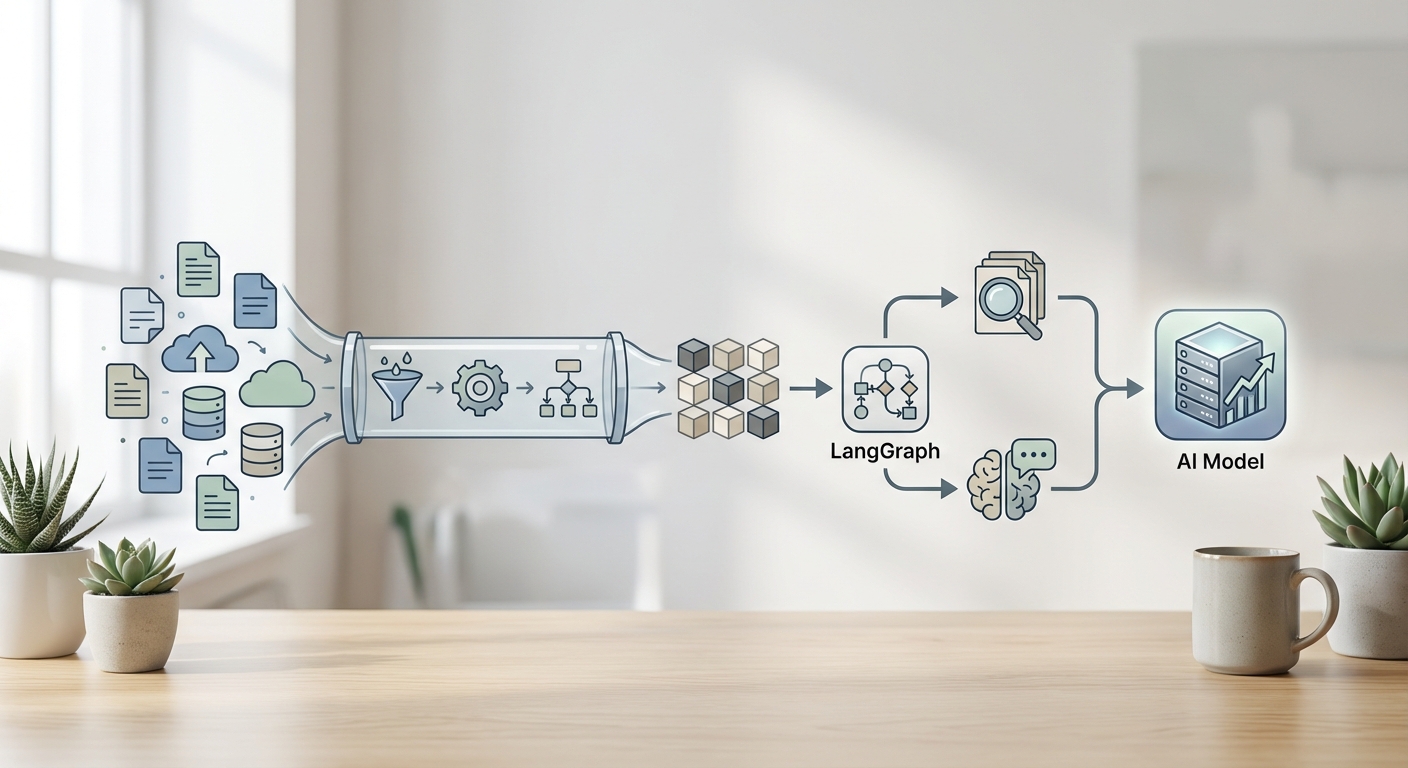
3. 파이프라인 구축과 실무 적용: LangGraph와 워크플로우
성공적인 AI 모델링은 단발성 코드가 아닌, 지속 가능한 파이프라인 구축에 달려 있습니다. 미드저니나 스테이블 디퓨전 같은 생성형 AI 모델 제작 스터디 사례를 보면, 데이터 전처리부터 모델 구축, 예측 결과 분석까지의 과정이 물 흐르듯 이어져야 합니다.
최근에는 LangGraph를 활용하여 커스텀 RAG 에이전트를 구축하는 사례가 늘고 있습니다. 여기서 중요한 전처리 전략은 '분기 판단'을 위한 데이터 구조화입니다. 사용자의 질문이 들어왔을 때, LLM이 벡터 스토어(Vector Store)에서 외부 지식을 가져올지, 아니면 자체 지식으로 즉시 응답할지를 결정하게 만드는 것입니다. 이를 위해서는 전처리 단계에서 데이터의 카테고리를 명확히 분류하고 태깅하는 작업이 선행되어야 합니다. 개발자 김지섭으로서 경험한 바에 따르면, 이러한 구조적 전처리는 추후 모델 튜닝 시간을 획기적으로 단축시켜 줍니다.