AI 모델 추론 성능 최적화 기법: 양자화(Quantization)와 가지치기(Pruning) 심층 분석
김지섭 개발자가 전하는 AI 모델 최적화 가이드. 추론 속도를 높이고 자원을 절약하는 양자화와 가지치기 기술의 원리와 실무 적용 팁을 알아봅니다.
AI 모델 경량화, 왜 필수적인가?
현업에서 AI 모델을 개발하다 보면, 성능(Accuracy)을 높이기 위해 모델의 크기가 기하급수적으로 커지는 경우를 자주 마주합니다. 하지만 연구 환경과 달리, 실제 서비스 환경에서는 제한된 리소스와 응답 속도(Latency)가 매우 중요한 요소로 작용합니다. 아무리 정확도가 높은 모델이라도 사용자에게 결과를 보여주는 데 1초 이상 걸린다면 좋은 서비스라고 할 수 없기 때문입니다.
특히 엣지 디바이스(Edge Device)나 트래픽이 몰리는 서버 환경에서는 연산 비용을 줄이는 것이 곧 서비스의 지속 가능성과 직결됩니다. 이러한 문제를 해결하기 위해 필수적인 기술이 바로 모델 경량화 및 최적화입니다. 오늘은 그중에서도 가장 효과적이고 널리 쓰이는 두 가지 기법, 양자화(Quantization)와 가지치기(Pruning)에 대해 심층적으로 분석해 보겠습니다.
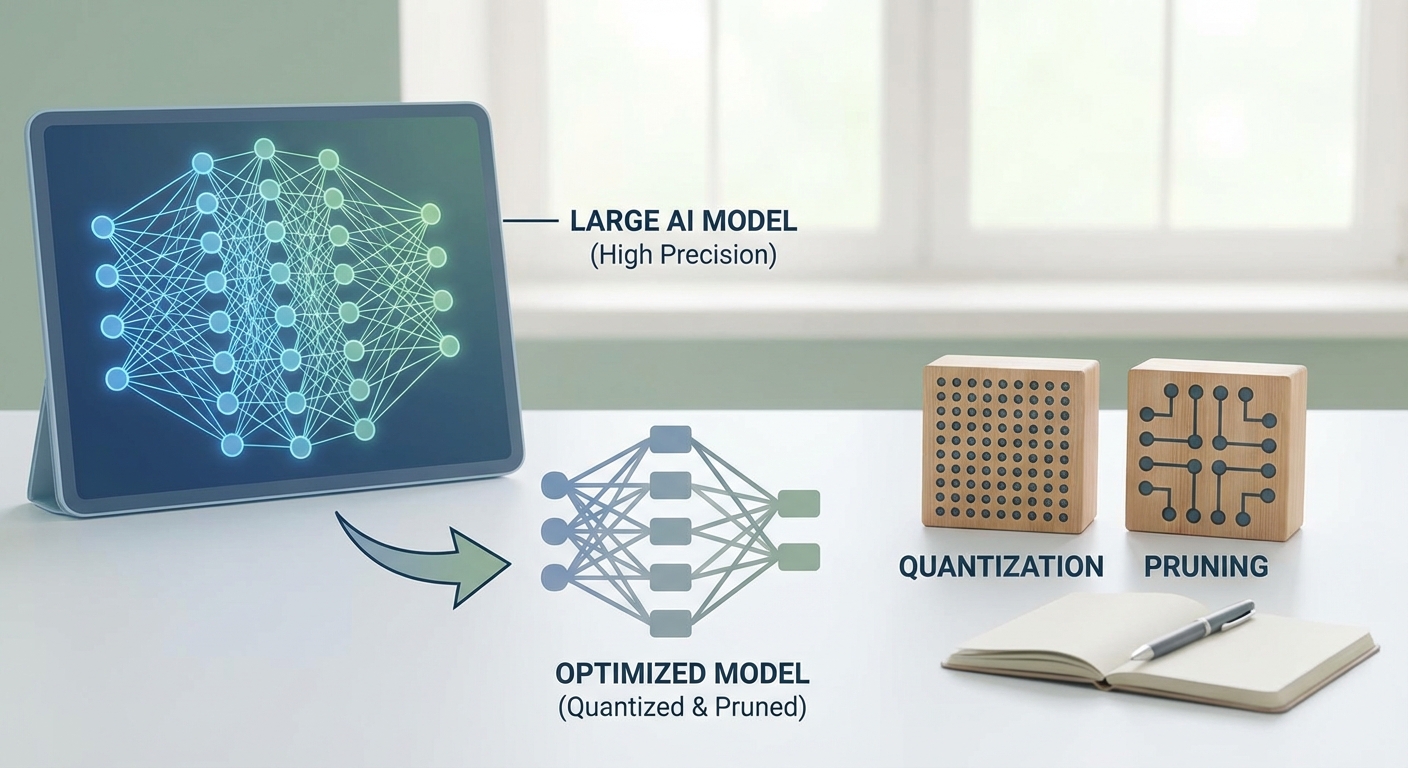
양자화(Quantization): 정밀도를 조정하여 효율성 극대화
양자화는 모델의 파라미터(가중치와 활성화 값)를 표현하는 비트 수를 줄이는 기술입니다. 보통 AI 모델은 32비트 부동소수점(FP32)으로 학습되는데, 이를 16비트(FP16)나 8비트 정수(INT8)로 변환하는 것이 핵심입니다. 데이터의 표현 범위를 줄임으로써 모델의 크기를 1/4 수준으로 줄이고, 메모리 대역폭 사용량을 감소시켜 추론 속도를 비약적으로 향상시킬 수 있습니다.
실무적으로 접근할 때 가장 먼저 고려해야 할 것은 'Post-Training Quantization (PTQ)'입니다. 이는 학습이 완료된 모델을 양자화하는 방식으로, 재학습 없이 빠르게 적용할 수 있어 효율적입니다. 만약 PTQ 적용 후 정확도 손실이 크다면, 'Quantization-Aware Training (QAT)'을 고려해야 합니다. 이는 학습 과정에서 양자화로 인한 오차를 미리 시뮬레이션하여 모델이 이에 적응하도록 만드는 기법입니다. 김지섭 개발자의 경험상, 대부분의 상용 서비스에서는 INT8 양자화만으로도 충분한 성능 향상을 얻을 수 있으며, 최근의 하드웨어 가속기들은 이러한 정수 연산에 최적화되어 있어 효과가 큽니다.

가지치기(Pruning): 불필요한 연결을 제거하다
가지치기는 생물학적 뉴런의 시냅스 연결 방식에서 영감을 받은 기법으로, 신경망에서 중요도가 낮은 가중치(Weight)를 제거하여 0으로 만드는 과정입니다. 모델의 가중치 중 절대값이 매우 작은 값들은 결과에 미치는 영향이 미미하기 때문에, 이를 삭제(Pruning)함으로써 연산량을 줄이고 모델을 희소(Sparse)하게 만듭니다.
가지치기는 크게 '비구조적 가지치기(Unstructured Pruning)'와 '구조적 가지치기(Structured Pruning)'로 나뉩니다. 비구조적 방식은 개별 가중치를 무작위로 제거하여 높은 압축률을 보이지만, 일반적인 하드웨어에서는 연산 가속 효과를 보기 어렵습니다. 반면, 구조적 가지치기는 채널(Channel)이나 필터(Filter) 단위로 통째로 제거하는 방식입니다. 이 방식은 GPU와 같은 병렬 연산 하드웨어에서 실질적인 속도 향상을 체감할 수 있어 실무에서 더욱 선호됩니다. 다만, 구조적 가지치기는 모델의 정확도에 더 큰 영향을 줄 수 있으므로, 제거 비율(Sparsity ratio)을 신중하게 설정하고 미세 조정(Fine-tuning) 과정을 거쳐야 합니다.

김지섭 개발자의 실전 최적화 전략 및 제언
모델 최적화는 단순히 기술을 적용하는 것을 넘어, 서비스의 요구사항과 하용 가능한 하드웨어 스펙 사이의 균형점을 찾는 과정입니다. 제가 AI 개발 프로젝트를 진행하며 얻은 실질적인 팁은 '순차적 접근'입니다. 처음부터 복잡한 가지치기나 QAT를 적용하기보다는, 먼저 학습된 모델을 ONNX Runtime이나 TensorRT와 같은 최적화 엔진을 통해 배포해 보고, 그 후 PTQ(학습 후 양자화)를 적용하여 성능 변화를 측정하는 것이 좋습니다.
양자화만으로도 목표하는 지연 시간(Latency)을 달성하는 경우가 많습니다. 만약 극한의 경량화가 필요하다면 그때 구조적 가지치기를 도입하고 재학습을 진행하는 것이 리소스 낭비를 막는 길입니다. 기술은 도구일 뿐, 가장 중요한 것은 사용자가 체감하는 서비스의 품질임을 기억하며 최적화 작업을 수행하시길 바랍니다.



