LLM 파인튜닝과 경량화: 실제 서비스 도입을 위한 최적화 전략
오픈소스 LLM을 실제 서비스에 적용하기 위한 SFT 전략과 모델 경량화 기법을 심층 분석합니다. 최신 Gemma 3 사례와 추론 파이프라인 최적화, 그리고 신뢰성 있는 AI 시스템 설계를 위한 개발자의 실질적인 가이드를 제공합니다.
오픈소스 LLM의 도메인 적응: Supervised Fine-Tuning (SFT)
최근 AI 개발 트렌드에서 가장 눈에 띄는 점은 거대 언어 모델(LLM)의 효율적인 미세 조정(Fine-tuning)입니다. 특히 오픈소스 LLM을 특정 도메인이나 태스크에 맞게 적응시키는 'Post-training' 단계의 중요성이 커지고 있습니다. 그중에서도 Supervised Fine-Tuning(SFT, 지도 미세 조정)은 가장 일반적이고 효과적인 전략으로 자리 잡았습니다.
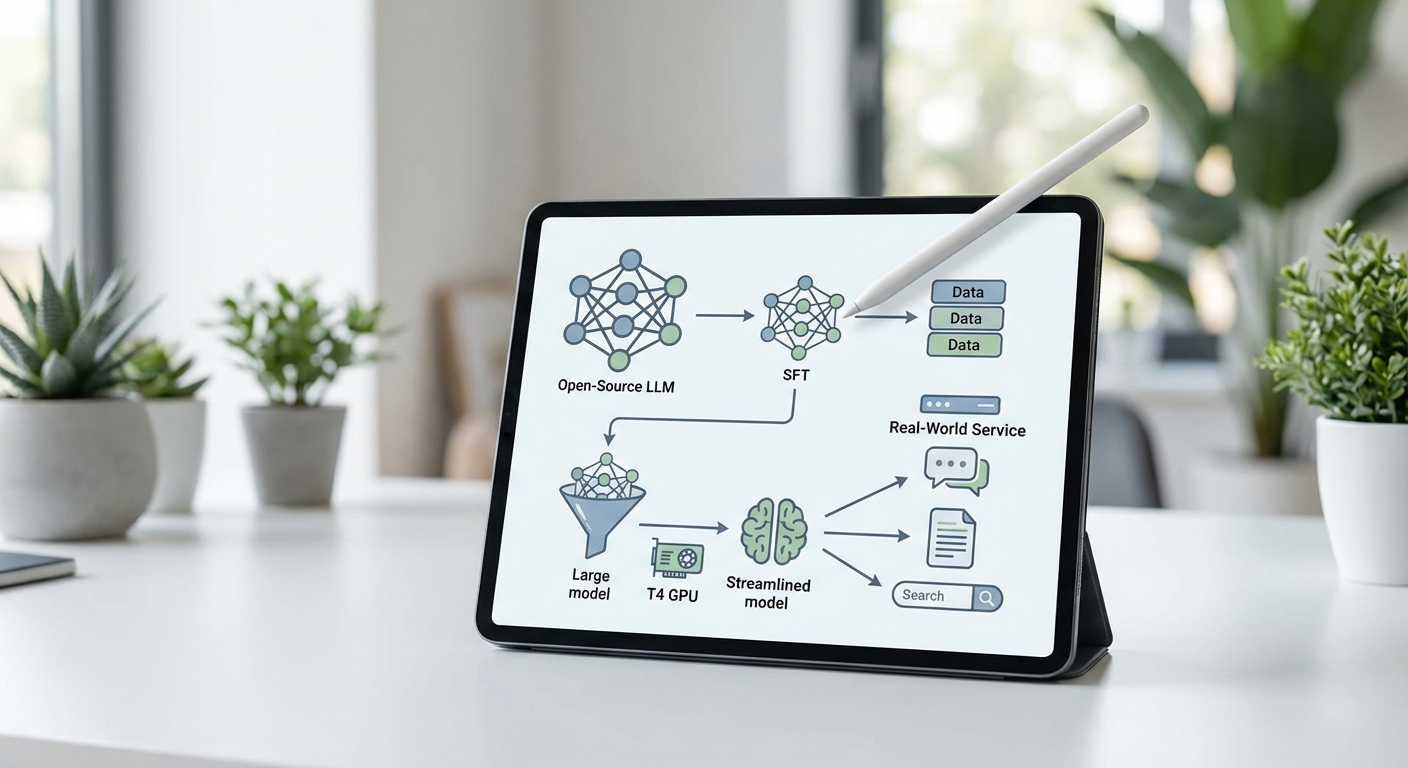
최근 업계 사례를 보면, 고가의 장비 없이도 T4 GPU 1장으로 구글의 Gemma 3 기반 sLLM(소형 거대 언어 모델)을 성공적으로 튜닝하여 서비스에 적용한 경우도 있습니다. 이는 막대한 컴퓨팅 자원이 필요한 사전 훈련(Pre-training)과 달리, 목적에 맞는 데이터를 선별하여 학습시키는 SFT 전략이 실제 비즈니스 환경에서 비용 효율적인 대안이 될 수 있음을 시사합니다. 개발자 김지섭으로서 바라볼 때, 무조건 큰 모델을 쓰는 것보다 우리 서비스의 목적에 맞는 모델을 선정하고 정교하게 튜닝하는 것이 프로젝트의 성패를 가릅니다.
서비스 속도와 비용을 잡는 모델 경량화 및 파이프라인 최적화
모델을 학습시켰다면, 다음 과제는 '어떻게 효율적으로 서빙할 것인가'입니다. 실제 서비스 환경에서는 응답 속도(Latency)와 운영 비용이 직결되기 때문입니다. 이를 해결하기 위해 모델 경량화(Model Light-weighting)와 추론 파이프라인 최적화는 선택이 아닌 필수입니다.
최신 연구 및 논의에 따르면, 모델의 크기를 줄이는 양자화(Quantization) 기술뿐만 아니라, 자원을 재활용하는 구조를 설계하여 에너지를 절감하는 것이 중요해지고 있습니다. 단순히 정확도만 높이는 것이 아니라, 어떤 요소까지 포함해 에너지를 계산할지 산업 표준을 고려하며 시스템을 설계해야 합니다. AI 개발자 입장에서는 PyTorch와 같은 프레임워크를 기반으로 모델 제조 라인을 최적화하여, 제한된 자원 안에서 최대의 성능을 이끌어내는 것이 핵심 역량입니다.

패턴 저장소를 넘어: 신뢰성 있는 시스템 설계 계층
LLM을 단순히 '똑똑한 챗봇'으로만 바라보면 한계에 부딪힙니다. 최근 AI 에이전트 및 AGI 관련 논의에서는 LLM을 방대한 '패턴 저장소(Pattern Repository)'로 정의하고 있습니다. 즉, 모델 자체는 확률에 기반하여 그럴듯한 패턴을 생성하는 도구일 뿐, 그 자체로 완벽한 논리적 추론을 보장하지는 않는다는 점을 인지해야 합니다.
따라서 실제 서비스 개발 시에는 LLM이 제공하는 풍부한 패턴 위에서 작동하는 새로운 소프트웨어 계층(Software Layer)에 집중해야 합니다. 이 계층은 모델의 환각(Hallucination)을 제어하고, 신뢰성 있는 추론을 유도하며, 비즈니스 로직을 강제하는 역할을 합니다. LLM 파인튜닝이 모델의 '지식'을 조정하는 것이라면, 이 시스템 설계는 모델의 '행동'을 규정하는 것입니다. 결과적으로 성공적인 AI 서비스는 모델의 성능과 견고한 시스템 아키텍처가 결합될 때 탄생합니다.